End-to-End ML Platform on AWS (MLflow + SageMaker)
AWS
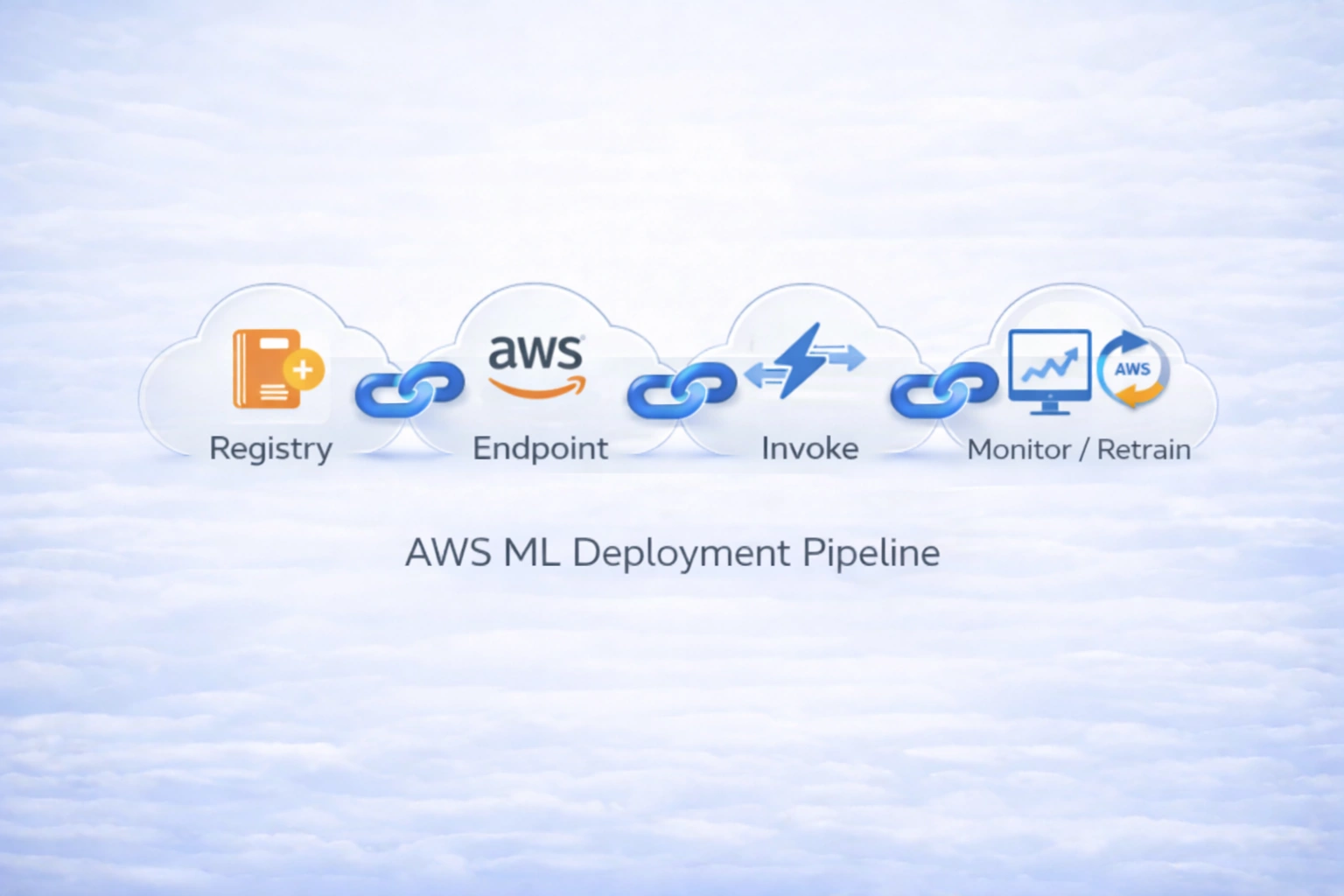
Production-grade ML platform with experiment tracking, model registry, and SageMaker-based training & deployment, provisioned using AWS CDK Infrastructure as Code.
AWS CDK (Python IaC)
MLflow
SageMaker
ECS Fargate
RDS MySQL
S3 Artifacts
MLflow tracking server on ECS Fargate with RDS + S3 backend
SageMaker training jobs integrated with remote MLflow tracking
Infrastructure fully provisioned using AWS CDK (IaC)
Model promotion and deployment via MLflow → SageMaker endpoints