AI‑Kubeflow Pipeline‑2
Training, Evaluation & Model Selection · Kubernetes‑Native MLOps
Production‑style ML training and evaluation pipelines using Kubeflow Pipelines with containerized components, artifact lineage, and metric‑driven model selection (KFP v2, MinIO, MLMD).
Project Summary
MLOps / Platform Engineering
Category
AI + MLOps + Platform Engineering (Kubernetes / Kubeflow)
Industry
Cross‑industry Enterprise AI Platforms / MLOps Infrastructure
Domain
Model Training Engineering / Pipeline Orchestration
Key Technologies & Concepts
Kubeflow native keywords
MLOps keywords
Problem & Objective
Why this project exists
Problems Solved
- Notebook‑driven training lacks reproducibility & governance
- Manual execution → inconsistent environments, fragmented metrics
- Limited visibility into experiment lineage and outcomes
Primary Objective
- Reproducible, pipeline‑driven ML training & evaluation on Kubeflow
- Containerized components + standardized artifact storage + metric‑driven model selection
Solution & Architecture
Kubeflow pipeline flow
Orchestration overview
Kubeflow Pipelines workflow orchestrates containerized components: data ingestion → training (Logistic Regression / Decision Tree) → evaluation → metric‑based comparison.
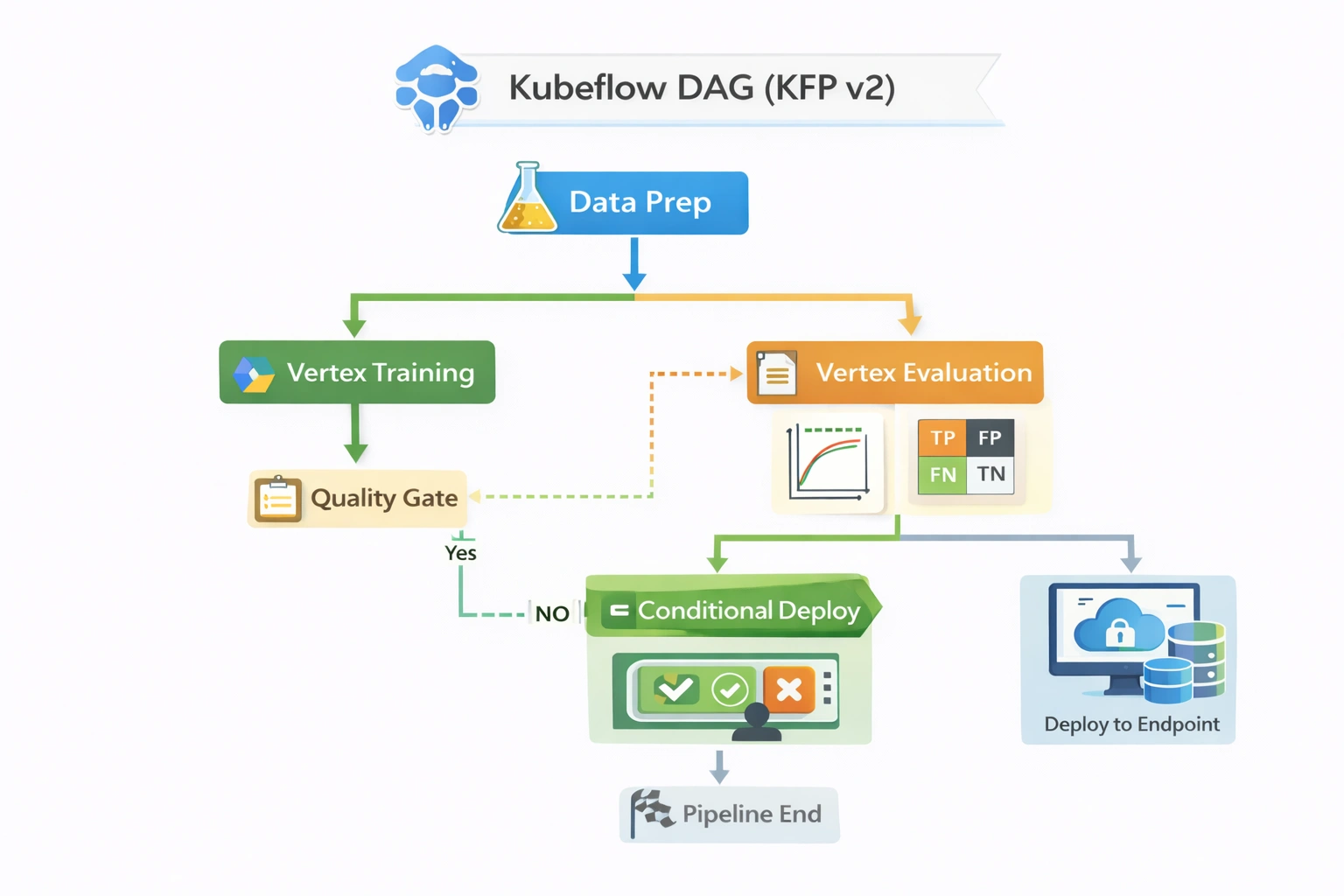
Components
- Download data (component)
- Training (scikit‑learn containers)
- Evaluation metrics (accuracy)
- Kubeflow Pipelines orchestration
- MinIO artifact storage
Platform & services
- Kubernetes + Kubeflow (KFP v2)
- Argo Workflows (execution engine)
- Docker (component images)
- MinIO + ML Metadata Store
- RBAC / K8s secrets
Skills & Technologies
Proficiencies demonstrated
Primary skills
- Kubeflow Pipelines (advanced)
- Kubernetes‑Native MLOps (advanced)
- scikit‑learn (model training)
- Docker / containerization
- YAML component specs
Secondary tools
- Argo Workflows
- MinIO, ML Metadata
- Python (core)
- Kubeflow UI / SDK
- Docker Hub
Kubeflow DevOps — Architecture & YAML mapping
Reference: Pipeline‑2 modelling
| Architecture Block | Kubeflow CI/CD / MLOps Construct (Pipeline‑2) |
|---|---|
| Source Repository | GitHub (Kubeflow modeling / pipelines repo) |
| Source Trigger | Manual (Kubeflow UI/SDK) or CI trigger (GitHub Actions) |
| CI Runner | GitHub Actions Linux runner (optional for compilation) |
| Build / Pipeline Execution | Kubeflow Pipelines (KFP v2: Data → Train → Evaluate → Condition) |
| Training Orchestration | KFP v2 on Kubernetes (Argo Workflows) |
| Data Processing | Kubeflow Pipeline Component (Python + sklearn) |
| Model Evaluation | Python + sklearn evaluation; accuracy metric |
| Artifact Storage | MinIO (S3‑compatible for datasets, models, metrics) |
| Container Registry | Docker Hub (versioned component images) |
| Model Registry | KFP run history + ML Metadata Store + MinIO artifact versions |
| Approval Gate | Pipeline Condition (metric threshold gate) |
| Security & Auth | Kubernetes ServiceAccounts + RBAC |
| Secrets / Config | Kubernetes Secrets + environment variables |
| Monitoring & Logs | Kubeflow Pipelines UI + Pod logs |
| Lineage & Governance | ML Metadata Store (inputs/outputs, lineage) |
| Infrastructure Backend | Self‑managed Kubernetes (Minikube/EKS/AKS/GKE) + Kubeflow manifests |
Pipeline‑2 implements Kubernetes‑native ML training & evaluation, open‑source equivalent of Vertex AI Pipelines.
Challenges & Resolutions
Technical hurdles
Key challenges
- Packaging training code into reproducible container images → standardised Dockerfiles per component
- Wiring artifact paths between components → Kubeflow artifact inputs/outputs
- Consistent metric logging across variants → centralised accuracy logging
- Experiment lineage → ML Metadata Store + KFP run history
Assets & References
Code, diagrams, study material
Note: Additional project materials (KFP v2 YAML, component specs) are shared selectively for interview / evaluation.