Model Deployment, Serving & Lifecycle Management
Kubernetes‑native inference for Kubeflow‑trained models
Project: AI‑Kubeflow Pipeline‑3 · Production‑style model serving using Kubernetes Deployments + KServe, with governed promotion, canary rollouts, and observability.
AI + MLOps KServe K8s Deployments Canary
Project Summary
Open‑source ML serving platform
Category
AI + MLOps · Platform Engineering (Kubernetes / Kubeflow)
Domain
Model Deployment Engineering / AI Serving Platforms (Open‑Source)
Focus
K8s‑native inference, endpoint lifecycle, canary rollouts
Key technologies & concepts
Kubeflow & Kubernetes serving stack
Problem & Objective
Why this deployment pipeline?
Problems solved
- Manual deployment → inconsistent serving, risky rollouts, no lineage
- Lack of standardized model packaging for Kubernetes
- No controlled canary/rolling updates for new versions
Primary objective
- Kubernetes‑native deployment pipeline for Kubeflow‑trained models
- Governed promotion, versioned endpoints, canary rollouts, and observability
Solution & Architecture
K8s serving + feedback loop
Deployment workflow
Selected model artifact → inference container build → Kubernetes Deployment / KServe InferenceService → online endpoint (Service/Ingress). Integration with Kubeflow Pipelines lineage (ML Metadata) and optional Prometheus/Grafana monitoring.
Rolling updates, canary traffic splits, health checks – all native on Kubernetes.
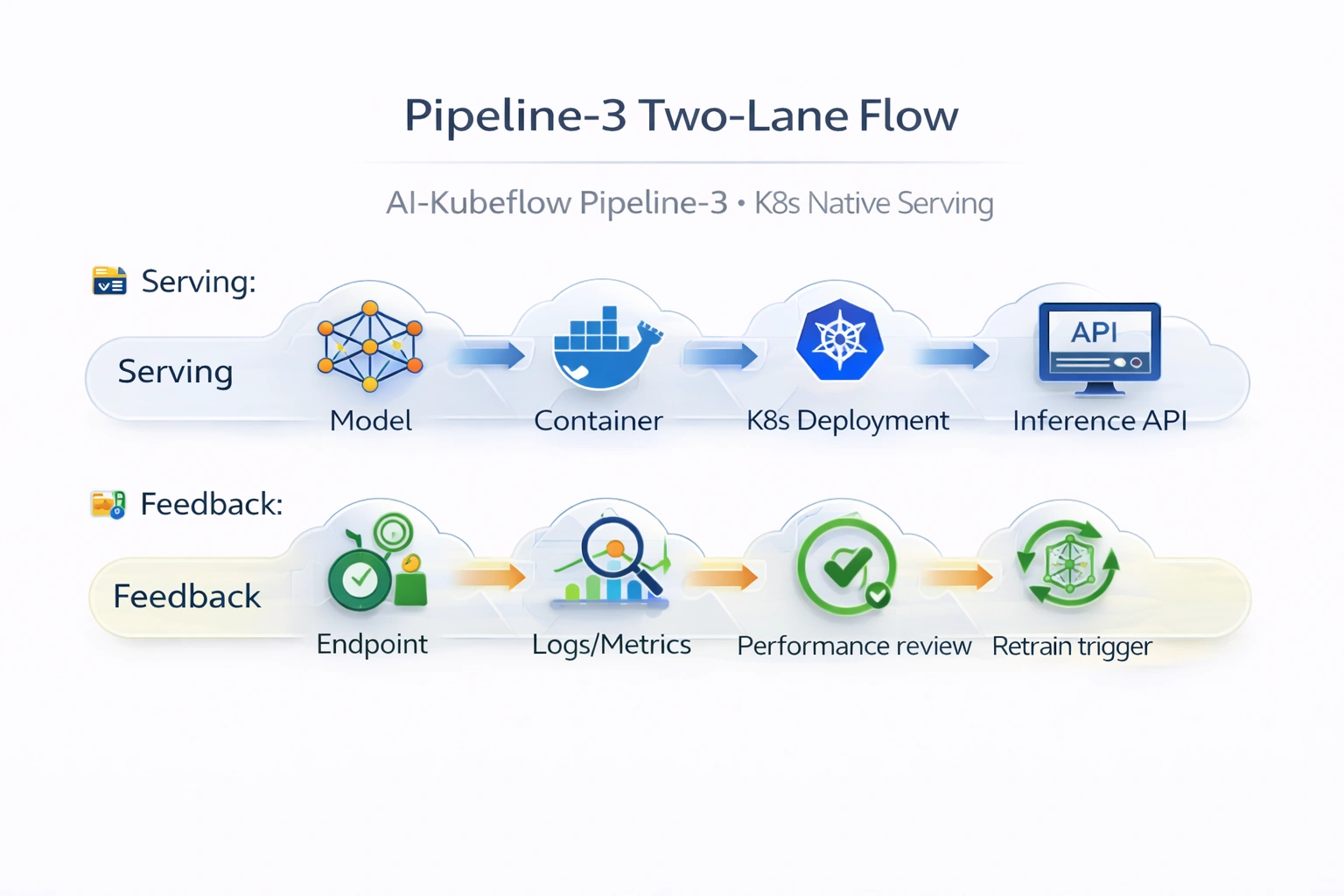
Key components
- Kubernetes Deployments + Services (serving runtime)
- KServe InferenceService (optional standardized ML serving)
- Docker (inference containerization)
- MinIO / Persistent Volumes (model artifacts)
- Kubeflow Pipelines + ML Metadata Store (lineage)
- Prometheus/Grafana (optional monitoring)
AI / DevOps Details
Serving automation & observability
AI/ML focus
Model Serving + Deployment Automation (MLOps – Online Inference on Kubernetes)
Implemented automation
- Packaging trained models into inference containers
- K8s Deployment/Service manifests (create, update, rollback)
- Integration with Kubeflow Pipeline outputs for promotion
- Optional KServe InferenceService for standardized API
Monitoring & optimisation
- Kubernetes pod logs + health/readiness probes
- Kubeflow lineage linking deployed model → training run
- Optional Prometheus/Grafana for latency/throughput
- Rolling updates / canary to minimise risk
Skills & Technologies
MLOps serving expertise
Primary skills
- Kubernetes‑Native Model Serving (advanced)
- Kubeflow Platform Integration (advanced)
- MLOps Deployment Architecture (advanced)
- Production ML Serving Design (advanced)
Secondary tools
- KServe (KFServing)
- Docker
- Python (inference services)
- YAML (K8s/KServe specs)
Kubeflow CI/CD · Architecture & YAML mapping
Pipeline‑3 (K8s deployment) constructs
| Architecture Block | Kubeflow / K8s Construct (Pipeline‑3 – Deployment) |
|---|---|
| Source Repository | GitHub (deployment / serving repo) |
| Source Trigger | Pipeline‑2 approval output (metric threshold) / Kubeflow UI |
| CI Runner | GitHub Actions Linux runner (optional image build) |
| Build / Deployment Execution | K8s manifests / KServe InferenceService specs |
| Serving Orchestration | Kubernetes Deployments + Services / KServe InferenceService |
| Model Packaging | Dockerized inference service from model artifact |
| Artifact Storage | MinIO / Persistent Volumes |
| Container Registry | Docker Hub (versioned inference images) |
| Model Registry (equivalent) | Kubeflow ML Metadata Store + MinIO artifact versions |
| Endpoint Platform | K8s Service (ClusterIP/NodePort/Ingress) or KServe endpoint |
| Traffic Management | K8s rolling updates / KServe canary traffic split |
| Approval Gate | Metric‑based gate from Pipeline‑2 (threshold passed) |
| Security & Auth | K8s Service Accounts + RBAC, Network policies |
| Secrets / Config | K8s Secrets + ConfigMaps |
| Monitoring & Logs | K8s pod logs + (optional) Prometheus/Grafana |
| Lineage & Governance | Kubeflow ML Metadata Store linking model → endpoint |
| Infrastructure Backend | Self‑managed Kubernetes (dev/prod) or EKS/AKS/GKE |
Production‑grade open‑source model serving with full lineage, canary rollouts, and K8s native observability.
Challenges & Outcomes
Technical resolutions
Key challenges
- Packaging trained artifacts into reproducible inference containers
- Standardised deployment pattern across environments
- Safe rollouts & rollback for new model versions
- Traceability between trained model and deployed endpoint
Resolutions
- Standardised inference container templates + versioned tags
- K8s Deployment/Service templates for consistency
- Rolling update strategies + optional KServe canary
- ML Metadata Store linking run → endpoint
Assets & References
Code, diagrams, study material