Vertex AI Deployment, Endpoints & Scheduling
Production‑grade model serving & continuous retraining on GCP
Project: AI‑GCP Pipeline‑3 · Endpoint lifecycle, traffic splitting, scheduled pipelines for model refresh. Online inference with managed Vertex AI Endpoints.
AI + MLOps Model Serving Blue/Green Deployment Vertex AI Scheduler
Project Summary
Model deployment & serving platform
Category
AI + MLOps · Cloud Platform Engineering
Domain
Model Deployment Engineering / AI Serving Platforms
Focus
Production online inference, endpoint management, retraining loops
Key technologies & concepts
Vertex AI serving stack
Problem & Objective
Why this deployment pipeline?
Problems solved
- Manual endpoint deployment → risk, drift, inconsistency
- No automated rollout or traffic management for new model versions
- Scheduled retraining missing → model stagnation
Primary objective
- Repeatable, production‑grade deployment pipeline with Vertex AI managed endpoints
- Versioned models, controlled traffic splits, scheduled retraining (continuous refresh)
Solution & Architecture
Deployment + retraining loop
Deployment pipeline design
Programmatic model upload to Vertex AI Model Registry, endpoint creation/reuse, traffic‑split deployment for new versions, and scheduled pipeline runs for continuous retraining & redeployment. All managed via Vertex AI SDK + KFP.
Autoscaling endpoints, versioned rollbacks, canary deployments — fully managed on GCP.
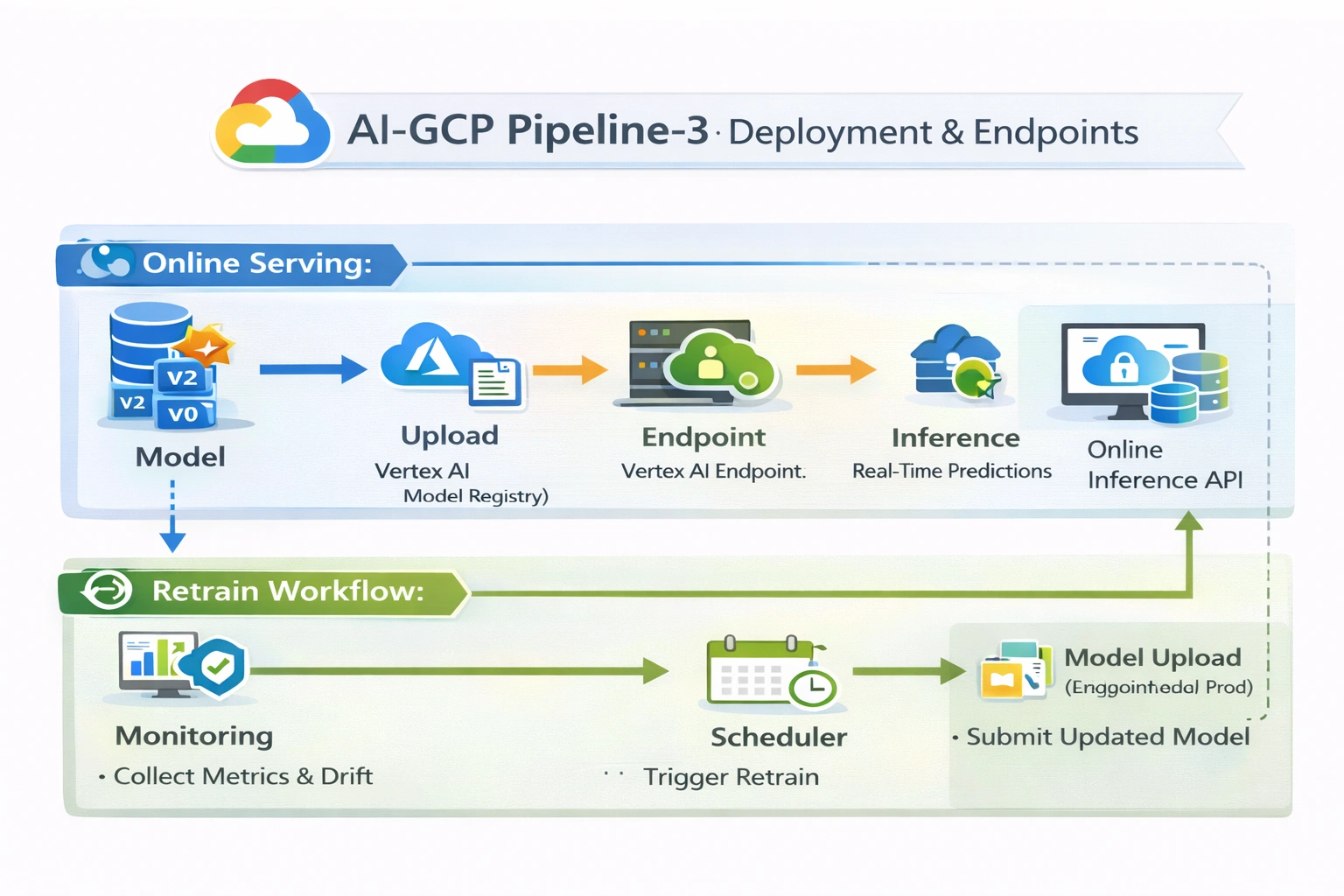
Key components (GCP)
- Vertex AI Model Registry (versioned models)
- Vertex AI Endpoints (managed inference)
- Vertex AI Pipeline Scheduler (cron retraining)
- GCS + Artifact Registry (artefacts & containers)
- Cloud Logging & Monitoring (observability)
- IAM service accounts (secure serving identity)
AI / DevOps Details
Model serving automation
AI/ML focus
Model Serving + Deployment Automation (MLOps – Online Inference)
Implemented automation
- Model upload to Vertex AI Registry
- Endpoint create/reuse logic
- Traffic‑split deployment (blue/green, canary)
- Scheduled pipeline runs for retraining
- Online prediction API invocation
Skills & Technologies
MLOps serving expertise
Primary skills
- AI Deployment Architecture (advanced)
- Vertex AI Endpoint Engineering (advanced)
- MLOps Production Deployment (advanced)
- Cloud AI Platform Engineering
Secondary tools
- Vertex AI SDK (Python)
- Kubeflow Pipelines v2
- scikit‑learn (model framework)
- GCS / IAM / Artifact Registry
GCP CI/CD · Architecture & YAML mapping
Pipeline‑3 (deployment) constructs
| Architecture Block | GCP CI/CD / MLOps Construct |
|---|---|
| Source Repository | GitHub (deployment pipeline definitions) |
| Deployment Trigger | Vertex AI Pipeline output (approved model from Pipeline‑2) |
| Deployment Orchestration | Vertex AI Model Upload + Endpoint Deployment APIs |
| Serving Platform | Vertex AI Endpoints (managed online prediction) |
| Online Inference API | Vertex AI Prediction Service (HTTPS endpoint) |
| Traffic Management | Vertex AI Endpoint traffic split (blue/green, canary) |
| Artifact Storage | Google Cloud Storage (model artifacts) |
| Model Registry | Vertex AI Model Registry (versioned models) |
| Approval Gate | Metric‑based gate in Pipeline‑2 (threshold passed) |
| Security & Auth | GCP IAM (endpoint access control, SA) |
| Monitoring & Logs | Cloud Logging + Vertex AI Endpoint Metrics |
| Scheduled Retraining | Vertex AI Pipeline Schedules (cron jobs) |
| Closed‑Loop Feedback | Endpoint metrics → retraining pipeline → model re‑upload |
Enterprise‑scale model serving with traffic splitting, canary rollouts, and cron‑based retraining.
Challenges & Outcomes
Technical resolutions
Key challenges
- Packaging models for Vertex AI serving containers
- Endpoint lifecycle (create vs reuse) logic
- Safe rollout of new model versions
- Operationalizing scheduled retraining on GCP
Resolutions
- Standardized model artifact layout
- Programmatic endpoint discovery & reuse
- Traffic‑split deployment (blue/green, canary)
- Vertex AI Pipeline scheduling with concurrency control
Assets & References
Code, diagrams, study material