Production-grade
infrastructure & operations
Four interconnected disciplines that together form a complete MLOps operating model — from the first code commit through automated deployment, container orchestration, infrastructure provisioning, and live production monitoring.
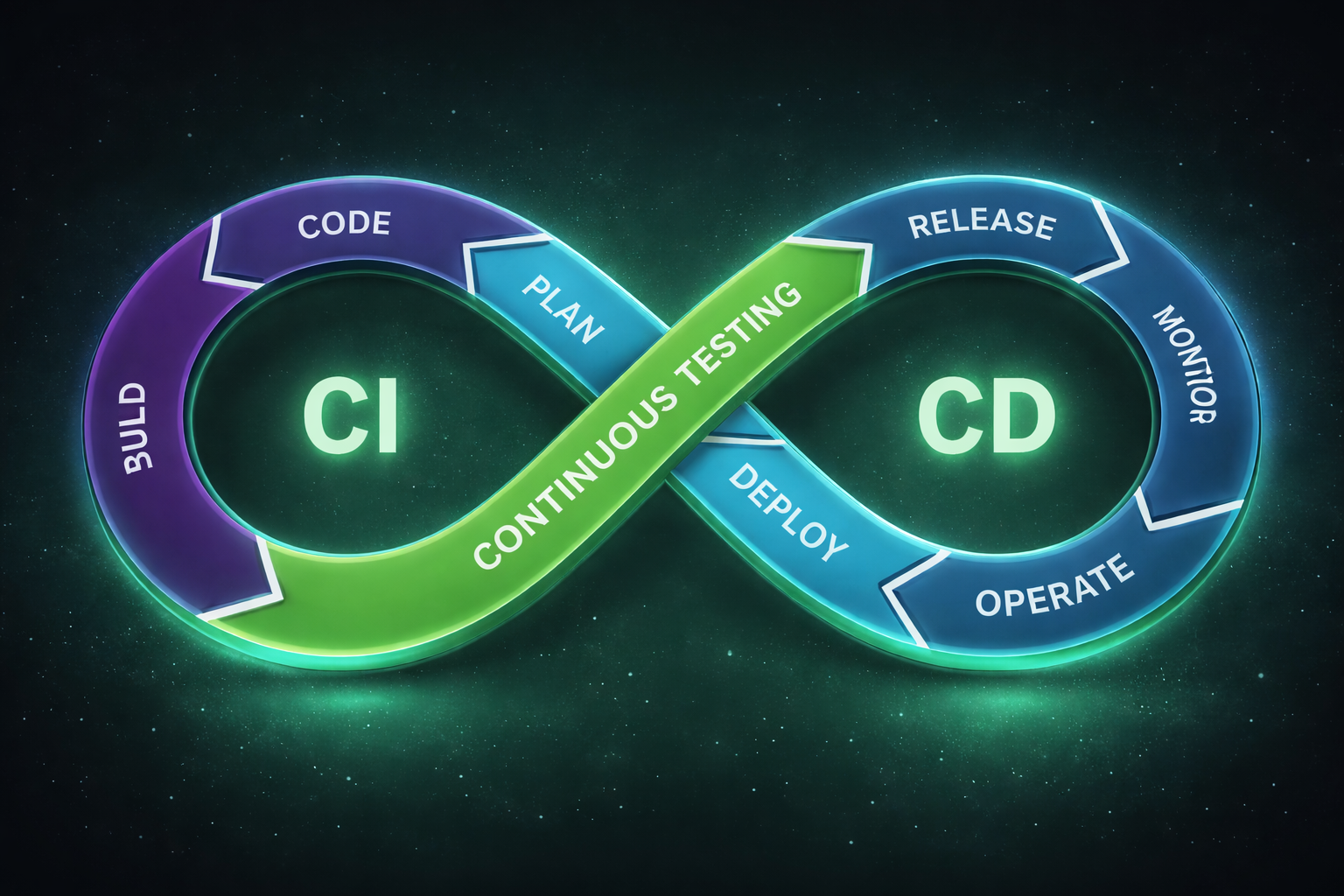
Design and implementation of robust CI/CD pipelines for automated testing, building, and deployment of applications and machine learning models.
- Automated testing and quality gates
- GitHub Actions and AWS CodePipeline
- Infrastructure deployment automation
- Security scanning and compliance checks

Kubernetes-based container orchestration for scalable, resilient deployment of microservices and machine learning models in production environments.
- Kubernetes and Docker expertise
- Auto-scaling and load balancing
- Service mesh implementation
- Production-grade configurations
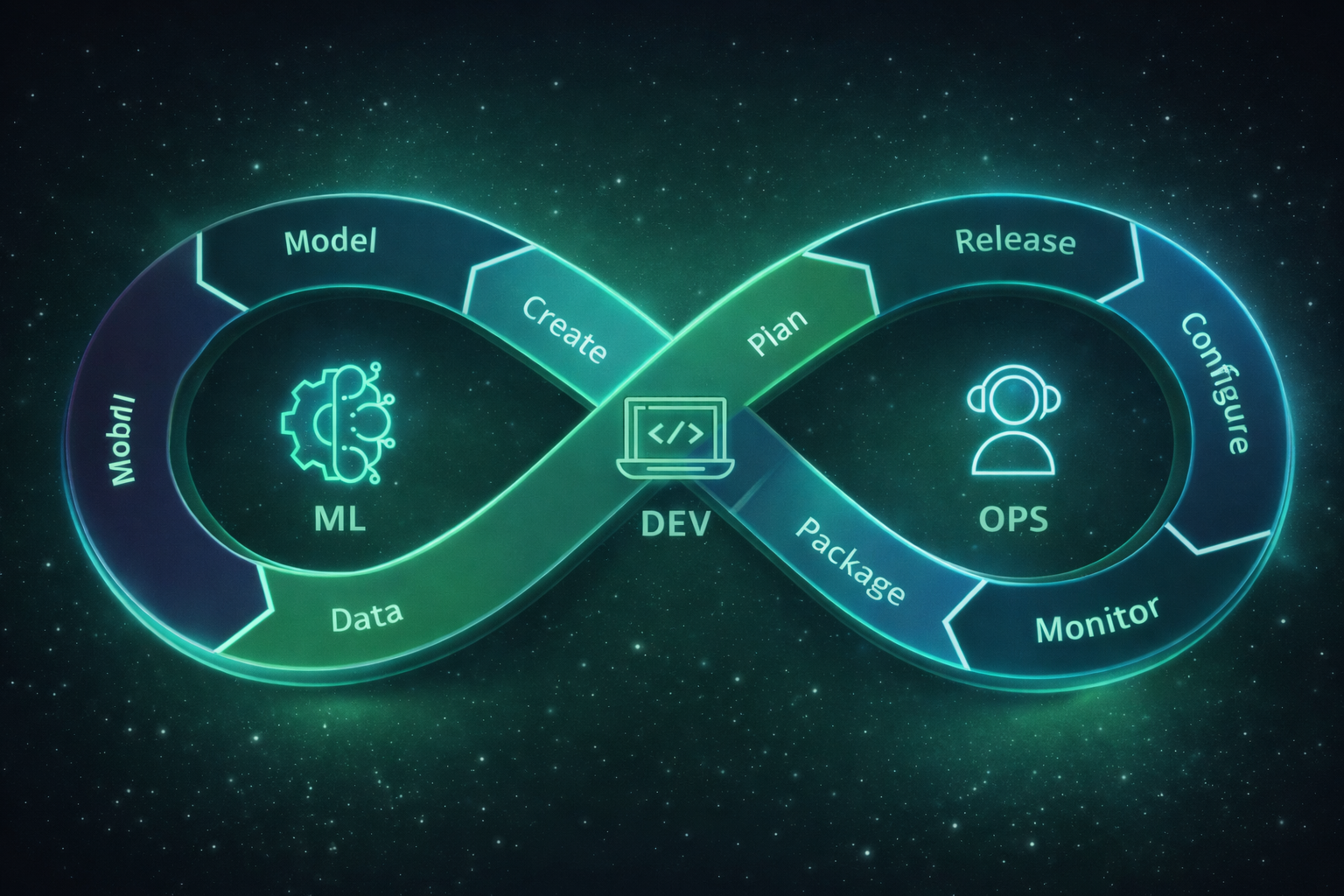
End-to-end machine learning operations including experiment tracking, model registry, deployment automation, and production monitoring.
- MLFlow and experiment tracking
- Model deployment and serving
- Performance monitoring and drift detection
- Automated retraining pipelines

Programmatic management of cloud infrastructure using Terraform, AWS CDK, and CloudFormation for reproducible, version-controlled environments.
- Terraform and AWS CDK
- Multi-environment deployments
- Cost optimization strategies
- Security and compliance automation