MLflow Platform Deployment on AWS ECS Fargate
Infrastructure as Code (CDK) | MLOps Platform Engineering
Deploying a production-grade MLflow tracking platform on AWS ECS Fargate using AWS CDK (Infrastructure as Code) for centralized experiment management. Complete infrastructure automation with RDS MySQL backend, S3 artifact storage, secure networking, and auto-scaling capabilities.
Project Summary
Comprehensive Project Overview
Project Category
MLOps / Cloud / DevOps (ML Platform Engineering)
Industry/Domain
Technology / Cloud Platforms / AI Infrastructure
MLOps Focus
ML Platform Engineering & Infrastructure Automation
Key Technologies & Concepts
Core Technologies Used
MLOps Platform Keywords
Problem & Objective
What problem did this project solve?
Problems Solved
- Lack of centralized, production-grade ML experiment tracking platform for cloud-based training jobs (SageMaker)
- Fragmented experiment logs causing poor reproducibility and no governed model lineage
- Manual infrastructure setup leading to inconsistencies and deployment delays
Primary Objectives
- Build a centralized, scalable MLflow tracking platform on AWS
- Enable reproducible experiment tracking and model artifact management
- Integrate with cloud training pipelines (SageMaker) using Infrastructure as Code
- Implement secure networking and access controls for production readiness
Solution & Architecture
Architectural Overview
Solution Overview
Deployed a production-grade MLflow tracking server on AWS ECS Fargate using AWS CDK, with RDS (MySQL) as the backend store, S3 as the artifact store, secure networking via VPC, and load-balanced access, enabling SageMaker training jobs to log experiments to a centralized ML platform.
AWS CDK (Python) provides Infrastructure as Code capabilities, enabling reproducible, version-controlled infrastructure deployment with comprehensive AWS service integrations.
The solution implements secure multi-tier architecture with public, private, and isolated subnets, NAT gateway for outbound access, and proper security group configurations to ensure production-grade security posture.
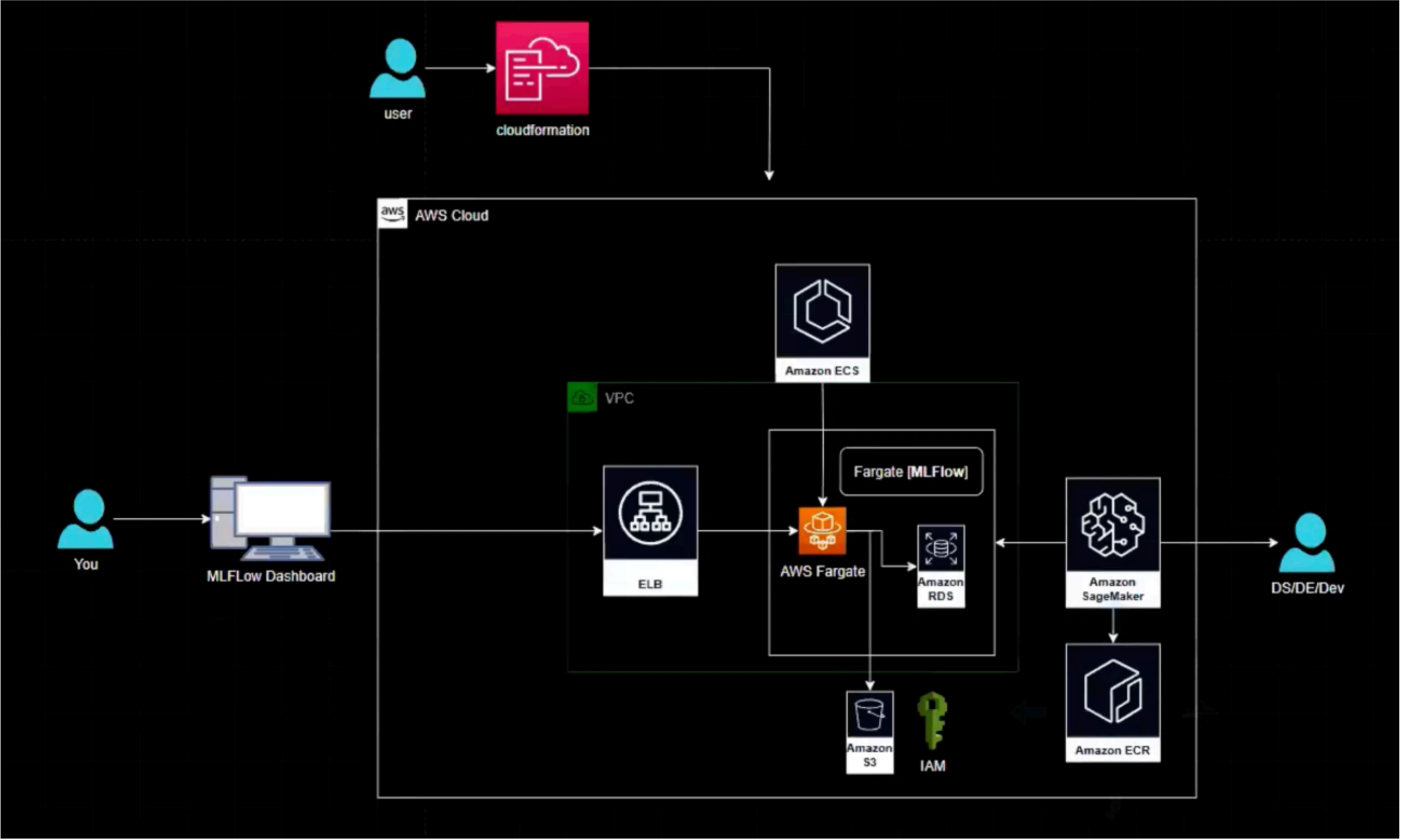
Key Components
- AWS CDK (Python): Infrastructure as Code framework for defining and provisioning cloud resources
- Amazon ECS Fargate: Serverless container orchestration for MLflow tracking server
- Amazon RDS (MySQL): Managed relational database for MLflow backend store
- Amazon S3: Object storage for MLflow artifacts and experiment outputs
- AWS Secrets Manager: Secure storage and rotation of database credentials
- Application Load Balancer: Public exposure and load distribution for MLflow UI/API
- Amazon VPC: Network isolation with public, private, and isolated subnets
Skills & Technologies Used
Technical Proficiency Demonstrated
Primary Skills
- AWS CDK (Python) - Advanced: Infrastructure as Code development and deployment
- AWS ECS Fargate (Container Orchestration) - Advanced: Serverless container management and scaling
- MLOps / ML Platform Engineering - Advanced: Experiment tracking platform design and implementation
- AWS Networking (VPC, Subnets, Security Groups, ALB/NLB) - Advanced: Secure cloud network architecture
Secondary Tools / Frameworks
- MLflow: Experiment tracking and model management platform
- Docker: Containerization of MLflow tracking server
- Amazon RDS (MySQL): Managed database service for metadata storage
- Amazon S3: Artifact storage for experiment outputs
- AWS Secrets Manager: Secure credential management
- Amazon CloudWatch: Logging and monitoring
Programming Languages
- Python: AWS CDK IaC development and MLflow service configuration
- YAML/JSON: CloudFormation templates generated by CDK
- SQL: Database schema management for MLflow backend
AWS DevOps Tools
Deployment Process & Configuration
How the infrastructure is provisioned and managed
Deployment Execution
- Infrastructure provisioning via AWS CDK CLI commands
- Automatic CloudFormation template generation from Python code
- Programmatic user setup with IAM permissions for CDK bootstrap
- Step-by-step deployment with rollback capabilities
Security & Networking
Security implementations in the MLflow platform:
- VPC with public, private, and isolated subnet configurations
- NAT Gateway for secure outbound internet access from private subnets
- Security Groups with least-privilege access rules
- IAM roles with granular permissions for ECS tasks
- Database credentials managed via AWS Secrets Manager
- RDS instance deployed in isolated subnet without public access
Technical Challenges & Resolutions
- Challenge: IAM permission setup for CDK bootstrap and ECS task roles
- Resolution: Implemented granular IAM policies with principle of least privilege
- Challenge: VPC networking (private subnets, NAT, service connectivity to RDS/S3)
- Resolution: Designed multi-tier VPC architecture with proper routing tables
- Challenge: Secure secret management for database credentials
- Resolution: Integrated AWS Secrets Manager with automatic credential rotation
- Challenge: Correctly wiring MLflow backend store (RDS) and artifact store (S3)
- Resolution: Environment variable injection and IAM role permissions
- Challenge: Exposing MLflow securely via load balancer without public DB access
- Resolution: ALB in public subnet with target groups pointing to private ECS tasks
AWS CDK Commands & Setup Process
Step-by-step deployment instructions
npm install -g aws-cdk
# Verify CDK installation
cdk --version
# Initialize CDK project with Python
cdk init app --language python
# Configure AWS credentials
aws configure
# Install Python dependencies
pip install -r requirements.txt
# Activate Python virtual environment
source .venv/bin/activate
# Bootstrap CDK toolkit in AWS account
cdk bootstrap
# Synthesize CloudFormation template
cdk synth
# Deploy the stack with parameters
cdk deploy --parameters ProjectName=mlflow1 --require-approval never
Why npm (Node.js) with Python? AWS CDK is implemented on top of a Node.js runtime, even when you write stacks in Python. Node.js + npm installs the CDK CLI, while Python is used to write your infrastructure code.
MLflow Components & Architecture
Four components of MLflow platform
Tracking
The MLflow Tracking component is an API and UI for logging information about your models. It allows logging of parameters, code versions, metrics, and output files from running the code, providing visualization for results.
- Log and query experiments using Python, REST, R, and Java APIs
- Record and visualize experiment results
- Model registry for version management
Projects
MLflow Project helps ML teams organize and manage their projects. It allows for reusable and reproducible projects with API and command-line tools that can run on any platform.
- Package format for reproducible runs
- Dependency and environment management
- Cross-platform execution
Models
MLflow Model helps package and deploy machine learning models. It supports different tools like Apache Spark and facilitates usage of models in diverse serving environments.
- Standard format for packaging models
- Multiple flavors (Python, Sklearn, TensorFlow, etc.)
- Easy deployment to diverse environments
Model Registry
MLflow Model Registry helps teams manage the lifecycle of an MLflow model. It allows for versioning and storage of models, providing tracking of model lineage and transitioning between stages.
- Centralized model store
- Model versioning and stage transitions
- Collaboration features with UI and APIs
Assets & References
Code, diagrams, study material
GitHub Repository
Complete AWS CDK implementation for MLflow on ECS Fargate with all infrastructure code and configurations.
Access Repository